By Rakesh Patel
By Rakesh Patel
Knowledgable chatbots have garnered attention from many businesses in the past few months. Especially for businesses to provide support to their clients. Whereas, Embeddings have made it easier with natural language processing (NLP) as it represents words and sentences in a high-dimensional vector space. Thus, computers can quickly learn, understand and interact with human agents.
Chatbots’ ability to generate on-demand and accurate responses plays a vital role while communicating with humans. And this is where embeddings come in, as they are useful in this context. With the help of embeddings, a type of machine learning technique, chatbots can analyze and read the input data for processing answers that are more meaningful and appropriate to the given context.
Now, if you are wondering what embeddings are and what role it plays in chatbot technology, this blog will help you shed more light on this topic. So, give it a full read.
Table of Content
Embeddings: Meaning, Types & Process
In simple words, it’s a machine-learning technique that converts human-readable text into a numerical representation so that computers can understand the language easily. It is a method used for transforming textual data into a specific format that can be read and analyzed by computers.
Basically, embeddings are the result of a machine learning model, which is being trained on text data, such as a book or the whole content available on the internet. Based on the content and context, the model then learns to assign a unique numerical vector, called embedding, to each word or phrase in the dataset.
Embeddings have a versatile role, and therefore, it’s an important tool in natural language understanding. Using embeddings, chatbot technology can interpret user input and provide appropriate responses as well. Embeddings allow chatbots to read human language so that they can produce meaningful responses by analyzing words and phrases to a numerical representation.
Types of embeddings
Here are the three types of embedding models used in NLP, so let’s check them out.
- Word embeddings: In natural language processing, these embeddings are the most popular. Each word is represented by a vector called an embedding, and these embeddings are typically trained by neural networks being fed a vast collection of training data. Word2Vec, GloVe, and fastText are all examples of word embedding models.
- Sentence embeddings: Whole sentences and paragraphs are represented as vectors in these embeddings. When the goal is to categorize text based on its general meaning rather than individual words, sentence embedding can be helpful. Doc2Vec and Universal Sentence Encoder are two popular examples of sentence embedding models.
- Contextual embeddings: While creating these embeddings, we consider the overall context in which a word or sentence appears. One word, for instance, may carry with it a variety of connotations based on the surrounding content. Models like ELMo and BERT can be used to teach embeddings in a specific context.
How does it work?
The goal of the embeddings is to learn the context of the text in such a way that it can be easily processed by machine translation techniques. Below is how embeddings actually work.
- Pre-processing the text data is the very first stage in embedding creation. A variety of methods, including tokenization, stemming, and the exclusion of stop words, is used to achieve clean and accurate text data.
- Then, mapping it to a high-dimensional vector space where every word or token is given its own separate vector. The vector is known as a row or column in a matrix, with each dimension of the vector corresponding to a distinct property or attribute of the word.
- Following learnings, the context in which each word appears in the text input is used to update the vectors. Typically, this is accomplished by training a neural network model on a body of text data, such as Word2Vec or GloVe. In this process, the network learns to predict the context of each word or token and adjusts the corresponding vectors to create meaning.
- Thereafter, they can be utilized as features in a machine learning model to perform a number of natural language generation tasks, including text classification, sentiment analysis, and language translation. The machine learning model can benefit from deep learning methods of the text’s meaning and context thanks to the high-dimensional vector representation.
The Role of Embeddings in Chatbot Response Generation
In simple language, Chatbots are basically automated bits of software that rely heavily on embeddings to generate accurate, high-quality, and personalized responses for multi-turn conversations. Here, we’ll delve into the significance of embeddings in creating outstanding user experiences through chatbot response generation.
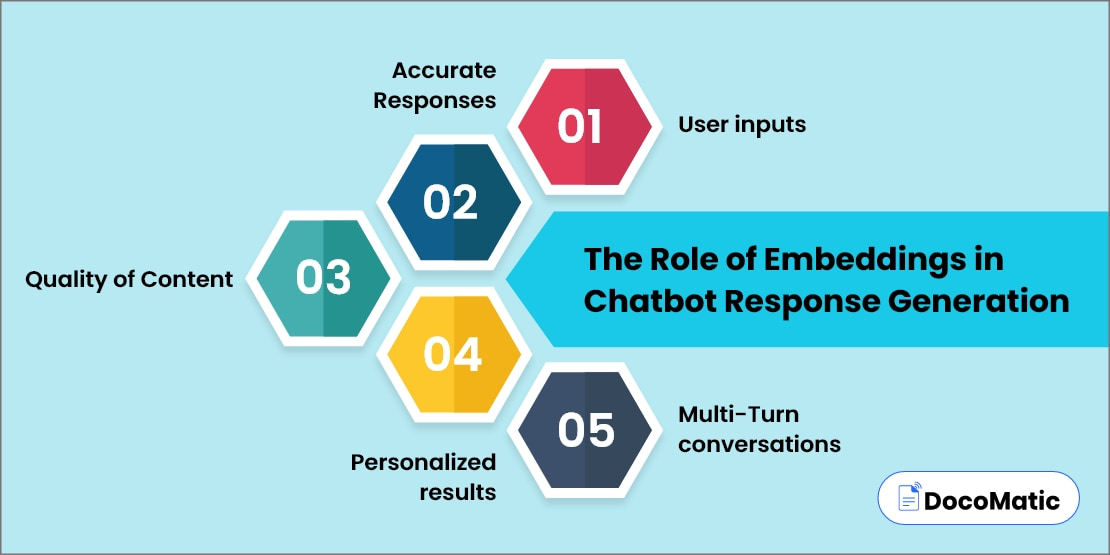
User inputs
Understanding the user’s input is the initial stage in creating a chatbot’s answer. The use of embeddings makes it possible for chatbots to interpret and act upon user input by projecting it into a high-dimensional space. Also, embeddings can allow chatbots to read not only individual words but also the entire context of the user’s input.
Accurate Responses
Since the chatbot can better deal with the user’s input, it needs to come up with a proper answer as well. Here embeddings play an important role in this process because they allow chatbots to choose the best response from a range of predefined responses. Chatbots can select the appropriate response based on how closely it matches the user inputs. To do so, it maps the model’s response to a high-dimensional vector space.
Quality of Content
Besides appropriate responses, the quality of content is crucial for providing a meaningful conversation with users. Embeddings allow chatbots to assess the content of their responses and make sure they are useful, interesting, and relevant to the conversation, all of which contribute to the bot’s ability to create high-quality responses. Later, it can customize its responses to individual demands by analyzing the sentiment, tone, and style of the response utilizing embedded content.
Personalized results
AI-powered chatbots must provide responses that are personalized to users’ unique requirements and interests to serve them better. Embeddings play a significant role at this point as they allow bots to generate personalized results from the user’s input and alter their responses accordingly. Plus, chatbots can quickly learn their users’ preferences by predicting their responses in a high-dimensional vector space.
Multi-Turn conversations
The multi-turn conversation is one of the essential features. If not considered, there would be only complex and dynamic interactions with users for sure. Here, again embeddings play a significant role in facilitating discussions with multiple users. It helps chatbots learn and remember previous encounters to have better responses in future interactions. And that’s how embeddings are saving us from boring conversations.
Pros and Cons of Using Embeddings in Chatbots
Embeddings in chatbots come with their own set of pros and cons, just like any other technology. Here, we will explore the pros and cons of using embeddings in chatbots.
Embeddings Pros:
- High accuracy: One of the key advantages of embeddings in chatbots is it provides highly accurate results. Chatbots can evaluate and process information from users more efficiently after mapping to a high-dimensional vector space.
- Customization: Chatbots can generate contextually relevant responses to individual users in a more thoughtful and relevant manner thanks to embeddings. It can generate more appropriate responses by analyzing inserted data and translating it to a dimensional vector space.
- Multilingual support: Chatbots can connect with users in more than one language through embeddings. Such a customer support chatbot can understand and respond to human language and intent by analyzing user input and projecting it into a high-dimensional space. This can be especially helpful for companies that have a global presence and deal with consumers who speak multiple languages.
Embeddings Cons:
- Developing issues: Embeddings are difficult to set up, so it needs to be done by someone who has technical knowledge. Otherwise, if someone is not friendly with natural language processing, it may create a long-term issue. This may disrupt the results as well.
- Requires robust training: Chatbots require an enormous database with the help of embeddings. So, this can be a challenge for developers who do not have access to large datasets. After all, the quality of the embeddings will depend on the quantity and quality of the training data.
- Overfitting: Another con is overfitting, which may happen if embedding is trained too closely in data training. It may cause embeddings to be somehow unable to generate new inputs. Such issues may result in the inaccuracy of chatbot responses, which can lead to poor performance on real-world data.
FAQs
The ideal example of word embedding is, let’s say, the word “lion”. Lion will be placed somewhere near other words like cheetah, tiger, or elephant, as can be potentially discussed in a similar context.
Simply, you can follow the below steps in order to embed your chatbot.
- Firstly, explore the web features
- Find the code for which you need to embed your chatbot
- Next, put your code into your web page
Basically, it is an algorithm that came into existence in 2013. The algorithm relies heavily on a neural network to learn more words from the text. Once it is mature enough, it can even capture synonyms or can also give suggestions for incomplete sentences.
Conclusion
On a conclusive note, it is likely that they will become a vital component of chatbot technology in the near future. Chatbots increasingly rely on natural language processing (NLP) to create more natural interactions with users, and embeddings play a key role in this process.
Moreover, many client interactions may be automated with the use of chatbots using an embedding platform or deep learning techniques in the future. This could possibly be to pull down the unnecessary expenses. As computing power increases, chatbots will be able to tackle more complex queries, thereby freeing up employees to focus on other tasks and boosting their productivity.
The technology comes with certain drawbacks, as one requires high knowledge of technical expertise to implement embeddings. Or else you may not get accurate responses and need specialized knowledge to implement it without any hassles.